KC2 修改有目录的 MOBI
缘由
vol.moe 上下载的《灌篮高手》,里面很多跨页内容被分到两页。正确处理应该跨页合并成一页,替代掉原来的两页。另外,有些页扫描不准,把邻页的边缘都截进来了。这两种情况,都可通过 KC2 ( Kindle Comic Creator ) 把 PS 处理后的页替代原来的内容。
几天后在 iPad 上看漫画,发现第一次处理时漏了一些未处理的瑕疵页。遂再补充完成,不过 KC2 编辑有目录的 EPUB 3 资源,会出现一些超链接错误,需要额外解决。本文就是解决 KC2 二次构建 EPUB 3 错误的一个案例。
错误出现
首先用 KindleUnpack 解压 MOBI 为 EPUB 3 格式,在 mobi8/OEBPS/Images/ 中选定瑕疵页,此张是边缘截边不准确:

用 PS 处理白边后,内容居中:

用 KC2 插入新图,构建 MOBI 时出现错误警告「无法解析目录中的超链接」:
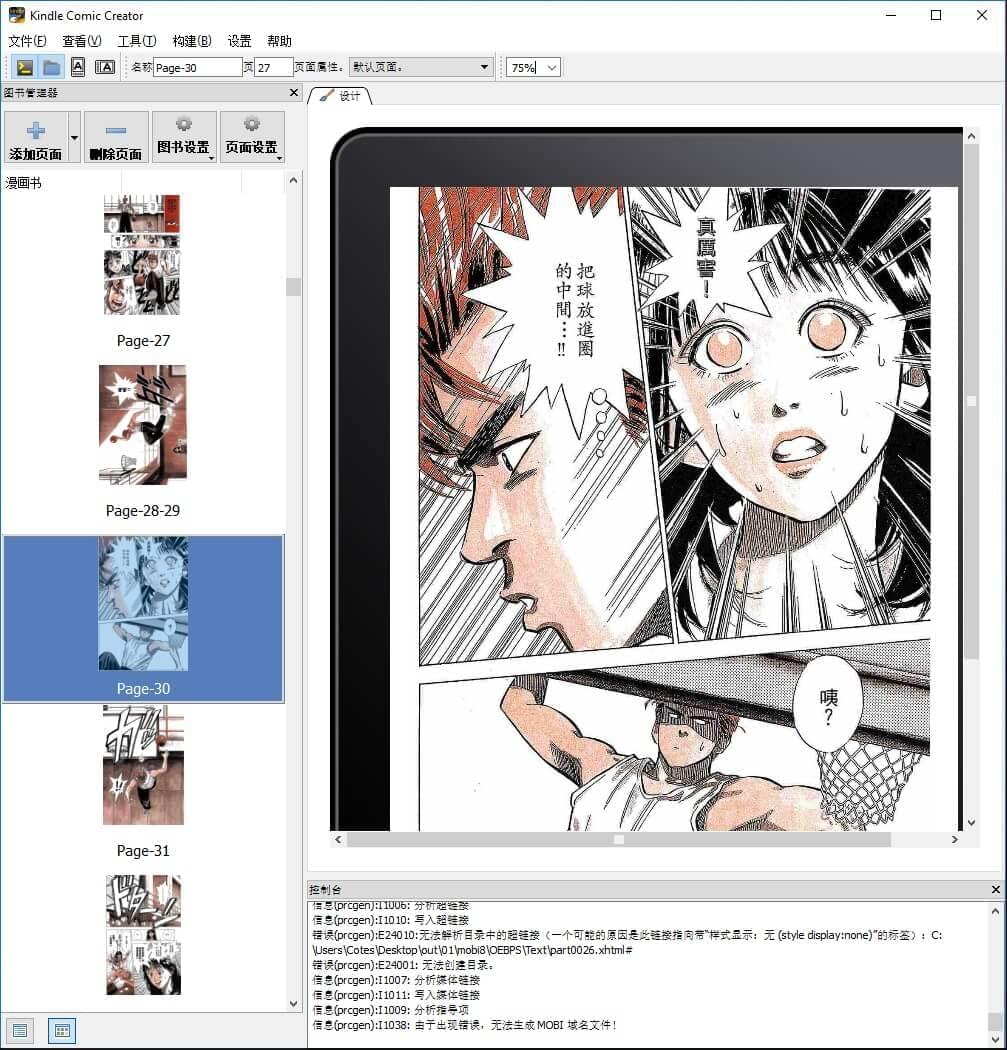
追踪问题
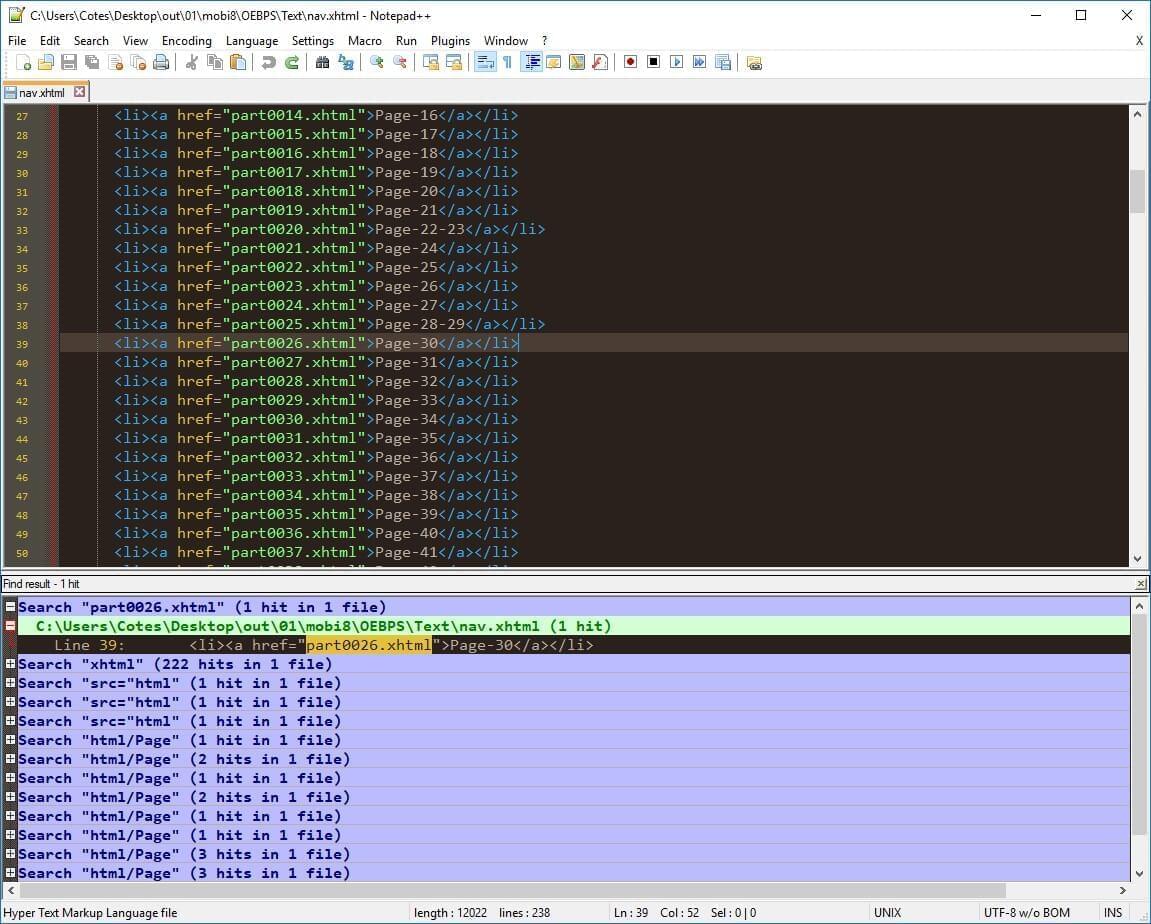
根据控制台错误提示,在 mobi8/OEBPS/Text/nav.xhtml 中找到引用 part0026xhtml 的问题行:
通过页码 Page-30 在 mobi8/OEBPS/toc.ncx 里找到正确的 src 路径:
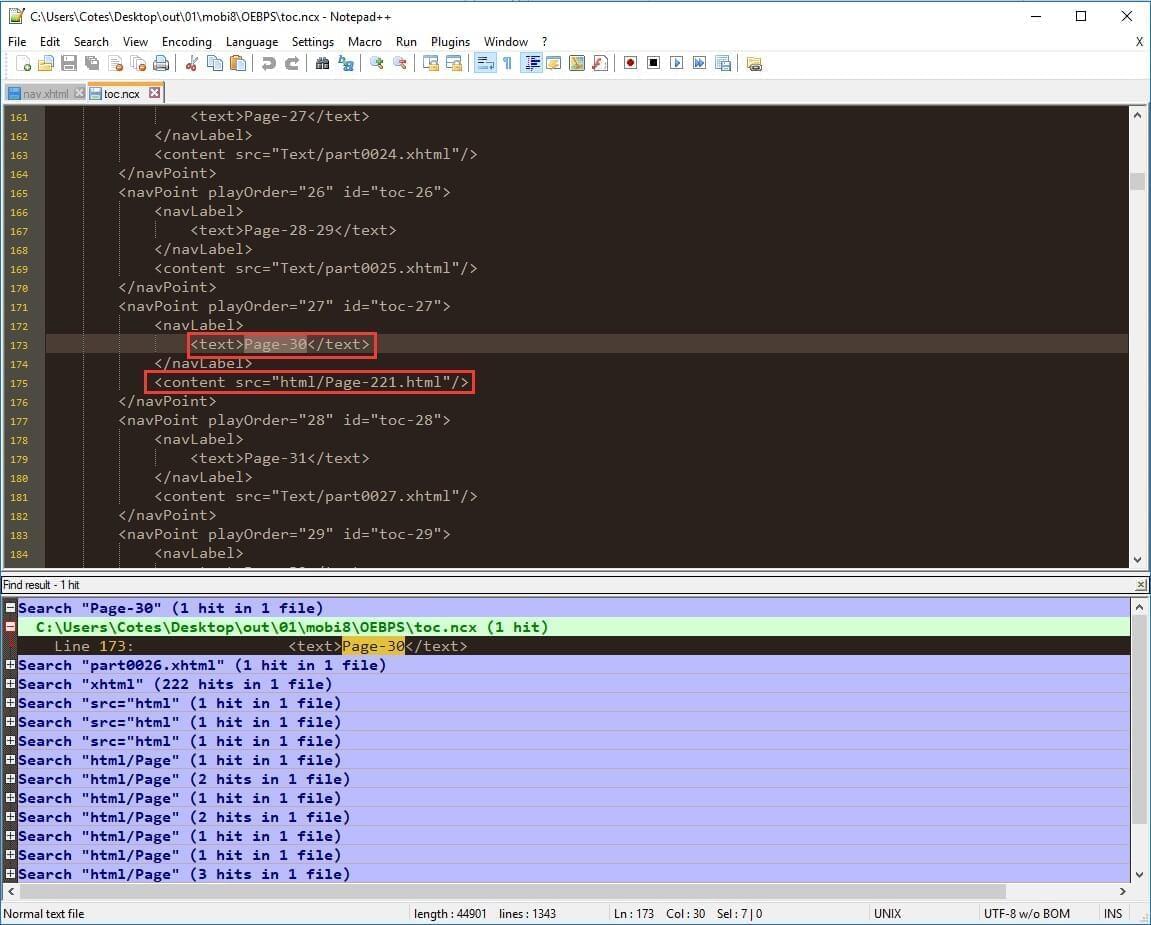
所以,问题症结在于:KC2 导入解压的 EPUB 3 文件内的 mobi8/OEBPS/content.opf 时,会从同级目录的 toc.ncx 及 Text/nav.xhtml 中导入目录信息。对于 已有目录的 MOBI 文件(如本例所述、此前经过 KC2 编辑的 MOBI,会自动生成页码目录),经过 KC2 更新图片资源再执行构建,会更新 toc.ncx 内容,使其与 GUI 显示一致,但却没有自动修改 nav.xhtml 中对图片引用链接。
修复错误
方法 1. 维持目录
注:此方法要求在 KC2 编辑完毕后实施。
此法又有两种选择:
1. 暴力的方式【荐】
nav.xhtml 是 KindleUnpack 执行 EPUB 3 格式解压时依照 toc.ncx 生成的内容,KC2 的构建 TOC 不依赖其目录(但不可移除整个文件)。故可直接清空 <ol>...</ol> 之间的内容,鉴于此法不需要脚本,手动执行即可快速完成,所以推荐。
2. 优雅的方式
把正确的相对路径内容修正到 nav.xhtml:
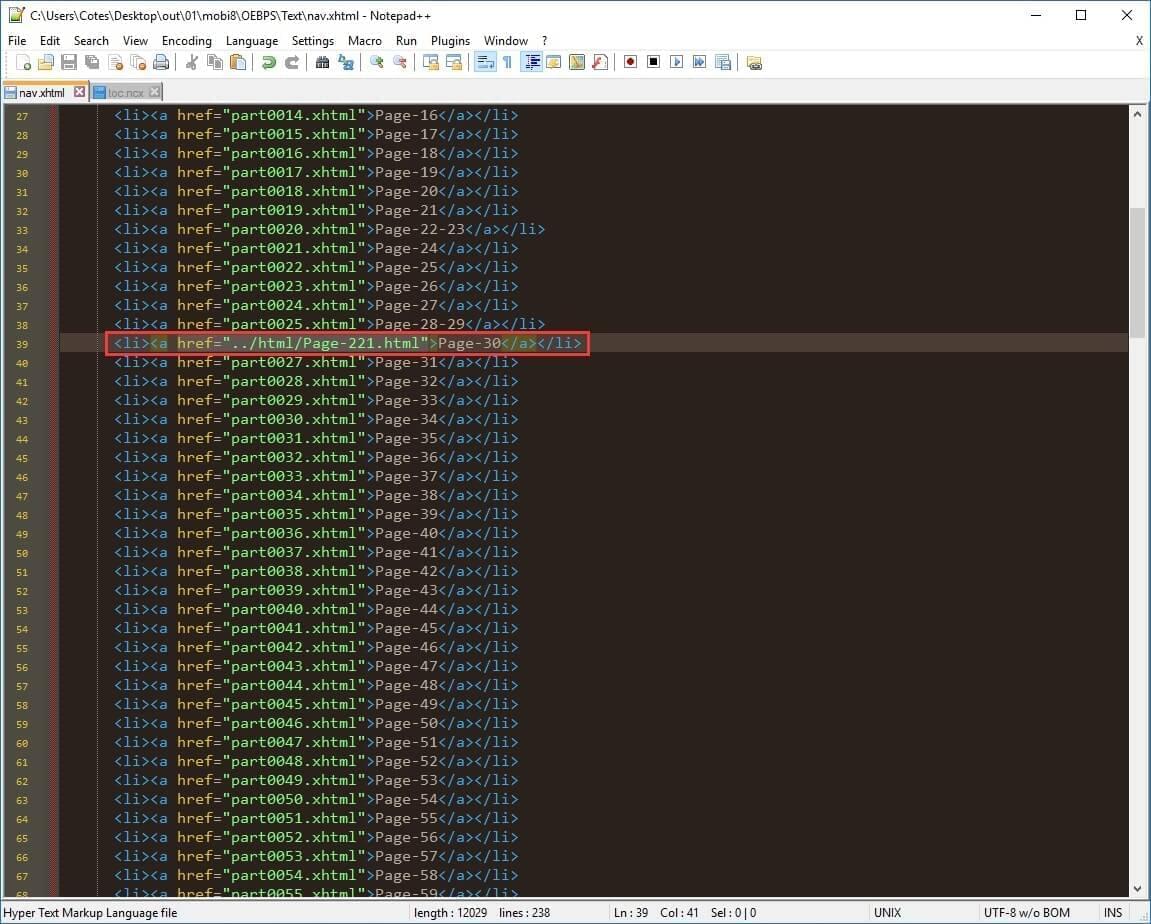
如果一次性修改了多张图片(有时多达两位数),手动修改效率低且容易出错,所以可使用 Python 脚本处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
This script will export the contents of toc.ncx to Text/nav.xhtml
Required:
- Python27
- BeautifulSoup4
'''
import os
from bs4 import BeautifulSoup
count = 0
src_path = "toc.ncx"
dest_path = "Text/nav.xhtml"
with open(src_path) as sf, open(dest_path) as df:
soup_src = BeautifulSoup(sf, "html.parser")
soup_dest = BeautifulSoup(df, "html.parser")
soup_dest.body.nav.ol.clear()
for nav_point in soup_src.find_all('navpoint'):
page = nav_point.navlabel.text.strip()
src = nav_point.content.get('src')
if src.startswith('Text'):
src = src[len('Text/'):]
else:
src = "../" + src
count += 1
print("\t{} -> {}".format(page, src))
tag_a = soup_dest.new_tag("a", href=src)
tag_a.append(page)
tag_li = soup_dest.new_tag("li", tag_a)
tag_li.append(tag_a)
soup_dest.body.nav.ol.append(tag_li)
dump = soup_dest.prettify()
os.remove(dest_path)
with open(dest_path, "w") as file:
file.write(dump.encode('utf-8'))
print("Done, updated {} urls.".format(count))
脚本逻辑是以 toc.ncx 内容为基准,将其内容导出到 nav.xhtml,将上述脚本放置于 toc.ncx 同级目录运行即可。
方法 2. 清空目录
如果 KC2 的 GUI 上编辑好的目录是没有具体意义的 Page-X,可以清空 MOBI 的目录信息。需要清除的内容有两部分:
- 清空
toc.ncx文件<navMap>...</navMap>之间的内容。 - 清空
nav.xhtml文件<ol>...</ol>之间的内容。
上述二法取其一,KC2 重新构建,错误驱散,生成了新的 MOBI。最后使用 KindleStrip 去除新 MOBI 里的 AWZ 部分缩小体积,即去冗。
后续优化
在上文错误出现中提及到,原图是 222 KB,经过 PS 修改后,输出为 975 KB。而这样变大的图片插进 KC2,再构建后的 MOBI 体积会比原来的大一点。具体涨幅与插入的 PS 处理图片数量成正比。
如本例,KC2 构建后的体积为 53.1 MB:
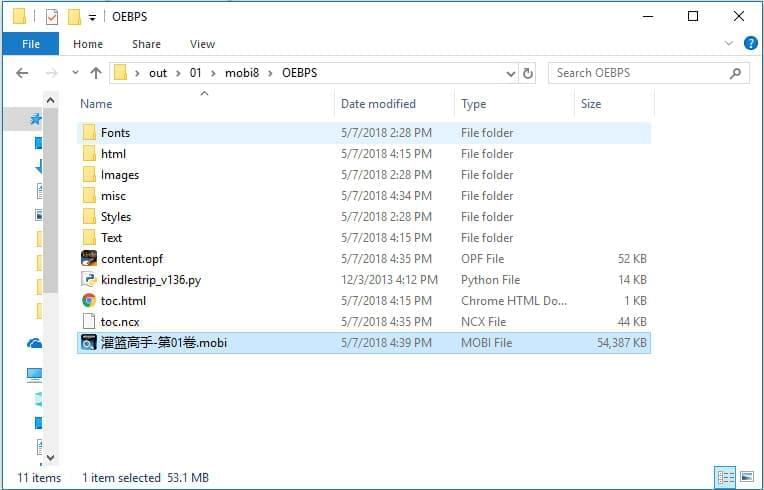
为了缩小体积,需要做一些重复的处理:
- KindleUnpack 解压上步 MOBI。
- KC2 构建上步产生的 content.opf。
- KindleStrip 最后分割上步 MOBI。
体积优化后的结果,体积缩小到 52.8 MB:
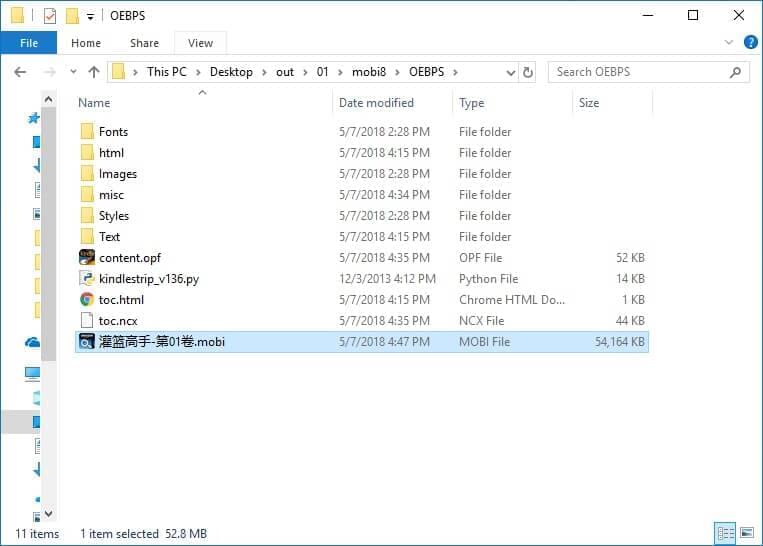
OK,至此得到了一个图页正确、体积小巧的完美 MOBI 文件了,可喜可贺。
其他方式
曾经考虑过,直接在 mobi8/OEBPS/Images/ 中替换处理好的图片,然后通过 KC2 导入图片新建生成 MOBI,免除修改 nav.xhtml 之苦。可惜 KC2 新建的 MOBI 体积太过庞大,譬如 60 MB 的文件,KC2 新建出来的可达 100 MB。所以作罢,不考虑 KC2 新建。
此外,如果可以不需要 EPUB 3 特性的话,在 KindleUpack 解压 MOBI 的时候可选择输出为 epub2 格式,这样就没有 nav.xhtml 文件的存在,也就可以省去了更正 nav.xhtml 的步骤了。
总结
根据此次宝贵的经历,现得出一套处理 KC2 二次(或以上)构建 EPUB 3 的流程:
nav.xhtml清除目录或用脚本修正中的图片链接。- KC2 重新构建 MOBI,然后 KindleStrip 去冗。
- 解压上步 MOBI,再一次 KC2 构建 → KindleStrip 去冗。